
I’ve been doing geospatial work for over thirty years. The last several have involved serious integration of large language models (LLMs) into professional GIS workflows. Not as a curiosity. As a practical tool I rely on at BlueLens Analytics. I want to give you an honest account of what that actually looks like, because the LinkedIn discourse on this topic is mostly useless.
Here’s the thing nobody is saying clearly: GIS is, structurally, one of the best domains in existence for LLM-assisted work. Not because large language models are magic, but because geospatial data is inherently machine-readable and machine-writable. Geometries are formal. Coordinate reference systems are documented specifications. Raster band math is arithmetic. Attribute schemas are typed. There is no ambiguity in what a reproject or a dissolve is supposed to do. When I describe a workflow to a model like Claude, it understands the domain. It knows what a spatial join is. It knows the difference between a feature class and a layer. It can reason about topology. That’s genuinely useful.
So where’s the problem?
The problem is execution at scale. And if you’ve spent any time building production geospatial pipelines, you’re going to recognize this immediately.
Consider a vector conflation workflow: harmonizing parcel boundaries from two county datasets with different collection vintages, different schema conventions, and enough geometric slop to make your eyes water. The logical architecture of that workflow is something a capable model can help you design in a single session. Attribute mapping strategy, candidate matching logic, confidence thresholds, exception handling for topological violations. It will give you a coherent blueprint. That’s real value.
But turn that same model loose to autonomously execute the full pipeline, and you are gambling. The issue isn’t intelligence. It’s state management across a long sequence of operations. Each processing step produces a new data state that the model has to reason about correctly going forward. A misread schema at step three doesn’t just affect step three. It propagates. A silently failed spatial index rebuild in step six means your intersect in step nine is running against stale geometry without complaint. The model continues. It doesn’t know to stop. By the time the output looks wrong, you’re debugging a compounding error that traces back four steps through operations that individually appeared to complete successfully.
This gets worse in specific environments. PyQGIS, QGIS’s Python API, is a particularly unforgiving surface for autonomous LLM execution. The API is large, version-sensitive, and environment-dependent in ways that aren’t always well-documented. QgsVectorLayer can return None under certain initialization conditions, and the model will carry that forward without surfacing it as a failure. This isn’t a criticism of the model. It’s a structural reality of working in a complex, mature open-source stack. The feedback loops that a human analyst uses automatically, things like visual inspection, sanity checks, and domain intuition, don’t exist in autonomous execution.
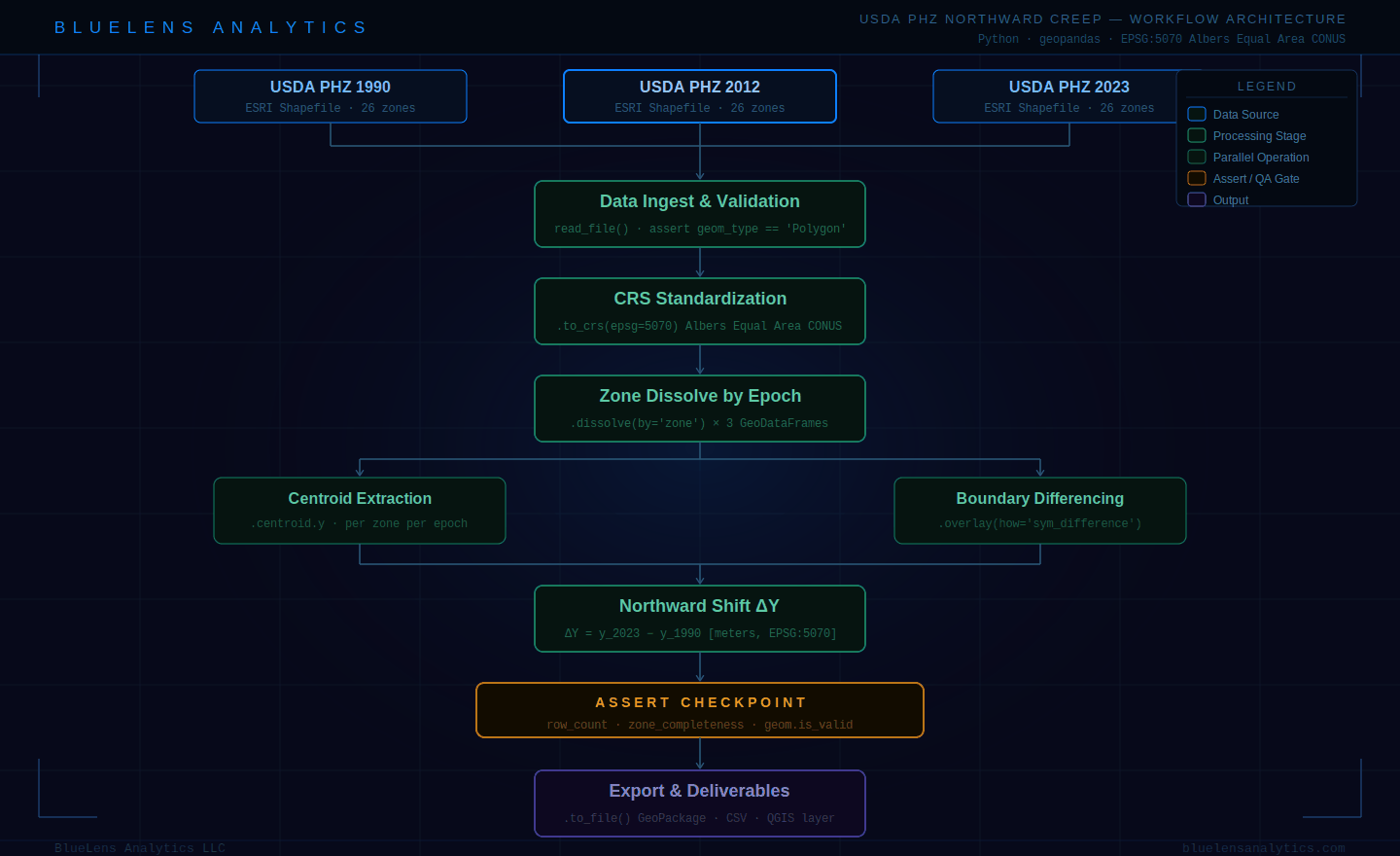
Flowchart diagram showing a Python/geopandas GIS workflow for analyzing the northward creep of USDA Plant Hardiness Zones across three epochs: 1990, 2012, and 2023. The pipeline flows from three data source inputs through validation, CRS standardization to EPSG:5070 Albers Equal Area, zone dissolve, parallel centroid extraction and boundary differencing operations, northward shift delta-Y calculation, a QA assertion checkpoint, and final export to GeoPackage and CSV. BlueLens Analytics.
The pattern that works
Here’s how I’m currently running non- and semi-agentic LLMs at BlueLens:
Use the model as your architect. Describe the workflow objective, the data environment, the constraints. Let it build out the full logical pipeline: every step, every decision point, every expected output type. Then review that architecture before you touch a line of code. This is where experienced eyes matter. A senior analyst reads that plan and immediately spots the step where the CRS assumption is going to fall apart, or where the attribute join is going to produce a many-to-one relationship nobody accounted for.
Then execute step by step, with explicit checkpoints. Not as a workaround. As engineering discipline. Build assertion logic after each stage: row counts, geometry validity checks, CRS verification, null field audits. When something fails an assertion, you stop. You look. You don’t let the pipeline continue against bad state because the model thought it was fine to proceed.
What you end up with is a workflow where large language models have done the cognitive heavy lifting on design, and that’s no small thing. A human analyst retains control at every execution decision point. The model is fast, thorough, and doesn’t get tired. The analyst has judgment, domain intuition, and the ability to recognize when something smells wrong before the geometry is already written to disk.
For open-source GIS specifically, this matters more than it does in black-box commercial tooling. When you’re in ArcGIS Pro with a licensed toolbox, a lot of failure modes are handled for you by the platform. When you’re running a geopandas pipeline with PyQGIS processing providers and GDAL under the hood, the environment is yours to manage. That’s powerful. It’s also where autonomous execution has the most ways to go sideways quietly.
The short version: Large language models are not ready to run your GIS workflows unattended. They are very good at thinking through them with you. Know the difference, build accordingly, and you’ll get real leverage out of it. Chase the full automation and you’ll spend more time debugging than you saved in the first place.
Chris Coffey is Senior AI Architect at BlueLens Analytics, a geospatial intelligence consultancy based in the North Carolina Sandhills.